Incremental Datalog with Differential Dataflows
Abstract
We propose a method of continuously executing Datalog queries over
data streams, by compiling them to differential
dataflows. This
work originated at ETH Zurich’s Systems
group, in collaboration with Frank
McSherry and Prof. Gustavo
Alonso.
This post is the first in an ongoing series on differential Datalog.
Most databases today provide a very straightforward access model: A client sends a query, which is promptly answered using whatever internal datastructures the DBMS is maintaining. In the context of scalable real-time data pipelines and stream processing architectures this access model becomes problematic. In order to retrieve live updates of query results, clients have to poll the database at regular intervals, thus placing significant load on the server.
Pub/sub architectures on top of durable logs do not have this problem, but can only propagate novelty at the granularity of a ‘topic’. Every consumer is responsible for joining, filtering, and aggregating new tuples into the query results they actually are interested in. Consequently, consumers must be able to keep up with the overall throughput on a topic, even though they might only ever work with a very small subset of messages.
Ideally we would want a system which allows clients to declare interest in information via the same powerful query languages we’re used to from relational databases, but is then able to update query results as new tuples enter the sytem — without computing full result sets from scratch.
Our work tackles a number of use cases.
Analysis of large, dynamic graphs. Graph processing is here to stay, as more and more organizations of all sizes and across varying industries rely on it.[6] Datalog with its recursive rules is well suited to express graph queries and executing those over larger and larger graphs as thousands of edges change every second seems like a worthwile challenge.
We note that the 22 software products in Table 1 have limited or no support for incremental and streaming computations.
- Sahu et al. 2018, The Ubiquity of Large Graphs [6]
Scalable view maintenance. We want to be able to maintain highly specific, potentially inter-dependent views for many thousand concurrent users over high-frequency event streams, subject to complex access policies. Of course we want users to be able to register and unregister queries at their leisure, just like they would with a SQL database.
Live, interactive web applications. Scalable view maintenance and near real-time propagation of changes allows us to efficiently treat web clients as just another database peer. This idea is laid out in “The Web After Tomorrow”[7], much more lucid than we can hope to achieve here. The following quotes and illustration are taken directly from Nikita’s post.
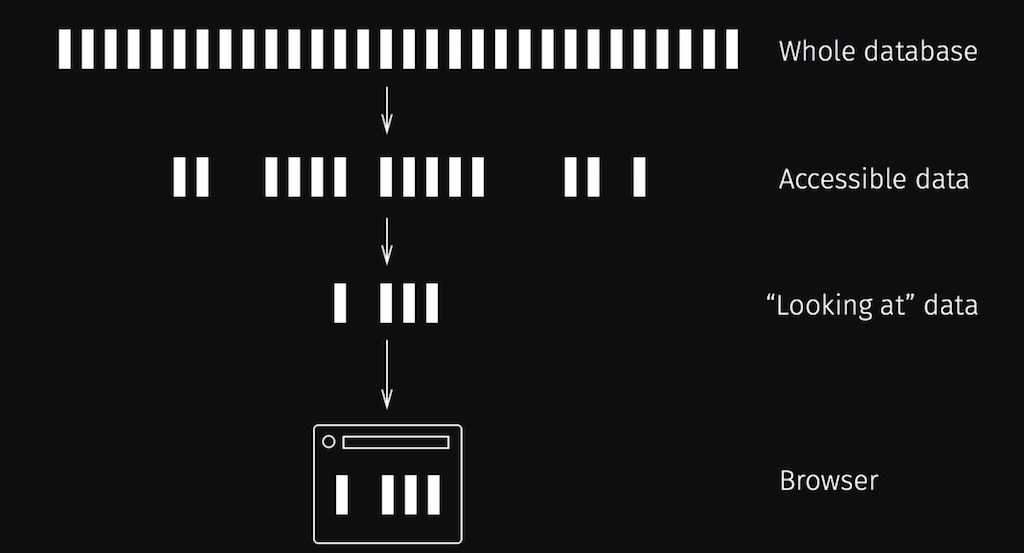
Web pages are usually pretty complex, they may track hundreds of different objects, they may track results of complex queries, they may track aggregations. And we might have thousands of live clients connected at the same time.
What we need here is probably a new query language, something like reversible SQL. We need our hypothetical ReversibleQL to run efficiently in both directions.
Related work
Naturally, various systems already exist in this interesting space. The Apache Kafka project introduced a streaming SQL engine not too long ago[4] and ‘changefeeds’ have been one of RethinkDB’s[5] most distinctive features for a while now. We wanted to provide such an incrementalized execution engine for the Datalog language and explore how well the powerful primitives offered by Differential dataflow would be suited to such an undertaking. This post is meant to provide a high-level overview of what we’re up too, in-depth discussions, comparisons, and examples will follow.
Differential dataflow
From its GitHub repository:
Differential dataflow is a data-parallel programming framework designed to efficiently process large volumes of data and to quickly respond to arbitrary changes in input collections.
Differential dataflow[0][1] (Differential) allows us to express
incremental computations (i.e. computations that will only do work on
the order of changes to the dataset) using the familiar language of
map, filter, join, group, and friends. Crucially, Differential
also allows us to have loops within our dataflow graph. These will
cause a sub-computation to execute repeatedly until a fixpoint is
reached, i.e. until the result set does not change anymore.
As Differential’s author Frank McSherry notes, Datalog programs map very nicely onto these primitives.
Declarative Differential Dataflows (3DF)
The 3DF project is an experimental implementation of an incremental Datalog engine based on Differential dataflow. It is meant to be used on top of systems like Datomic or Kafka, providing durability and any other features you’d expect from a proper database. 3DF consists of a library and server[2] written in Rust, providing dynamic synthetization of rather explicit query plans (like those found in SQL engines) into differential dataflows.
;; a simple query plan
{:Project
[{:Join [{:HasAttr [?e :name ?name]}
{:HasAttr [?e :age ?age]} ?e]}
[?e ?name ?age]]}
On top of this we provide a frontend[3] in Clojure(Script) which compiles Datalog expressions into query plans and offers a WebSocket interface for registering queries and receiving results. We did not want to invent a new flavour of Datalog (yet?) and thus implemented Datomic’s query language — which itself is modeled closely after Datalog.
;; a simple query for parents of the child with id 100
[:find ?parent :where [?parent :parent/child 100]]
Because 3DF is designed with long-running, continuously updated queries in mind, we are less concerned with the one-time cost of parsing, interpreting, and optimizing a query. By splitting the system this way we gain the freedom to experiment with different data models on the backend, and with query syntax on the frontend.
We’ll take a deep dive into 3DF internals in a future post.